class: center, middle, inverse, title-slide # STA 506 2.0 Linear Regression Analysis ## Lecture 4: Simple Linear Regression (cont.) ### Dr Thiyanga S. Talagala ### 2020-09-19 --- # Steps 1. Fit a model. 2. Visualize the fitted model. 3. Model Adequacy Checking 5. Interpret the coefficients. 6. Make predictions using the fitted model. --- # Fitted model ```r library(alr3) # to load the dataset ``` ``` Loading required package: car ``` ``` Loading required package: carData ``` ```r model1 <- lm(Dheight ~ Mheight, data=heights) model1 ``` ``` Call: lm(formula = Dheight ~ Mheight, data = heights) Coefficients: (Intercept) Mheight 29.9174 0.5417 ``` --- # Model summary ```r summary(model1) ``` ``` Call: lm(formula = Dheight ~ Mheight, data = heights) Residuals: Min 1Q Median 3Q Max -7.397 -1.529 0.036 1.492 9.053 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 29.91744 1.62247 18.44 <2e-16 *** Mheight 0.54175 0.02596 20.87 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 2.266 on 1373 degrees of freedom Multiple R-squared: 0.2408, Adjusted R-squared: 0.2402 F-statistic: 435.5 on 1 and 1373 DF, p-value: < 2.2e-16 ``` --- ## Interesting questions come to mind 1. How well does this equation fit the data? 2. Is the model likely to be useful as a predictor? 3. Are any of the basic assumptions violated, and if so, how series is this? > All of these questions must be investigated before using the model. > Residuals play a key role in answering the questions. --- 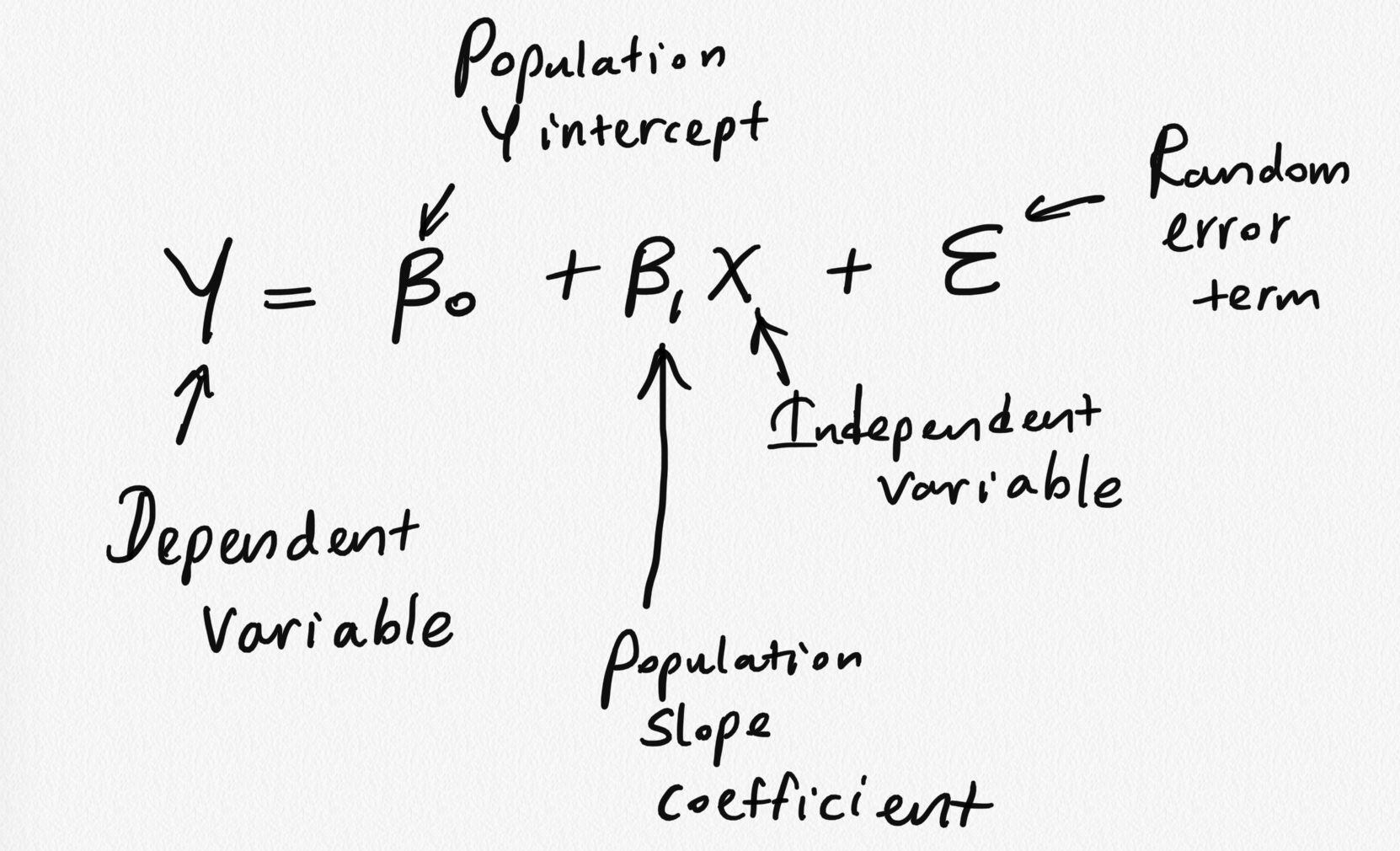 --- 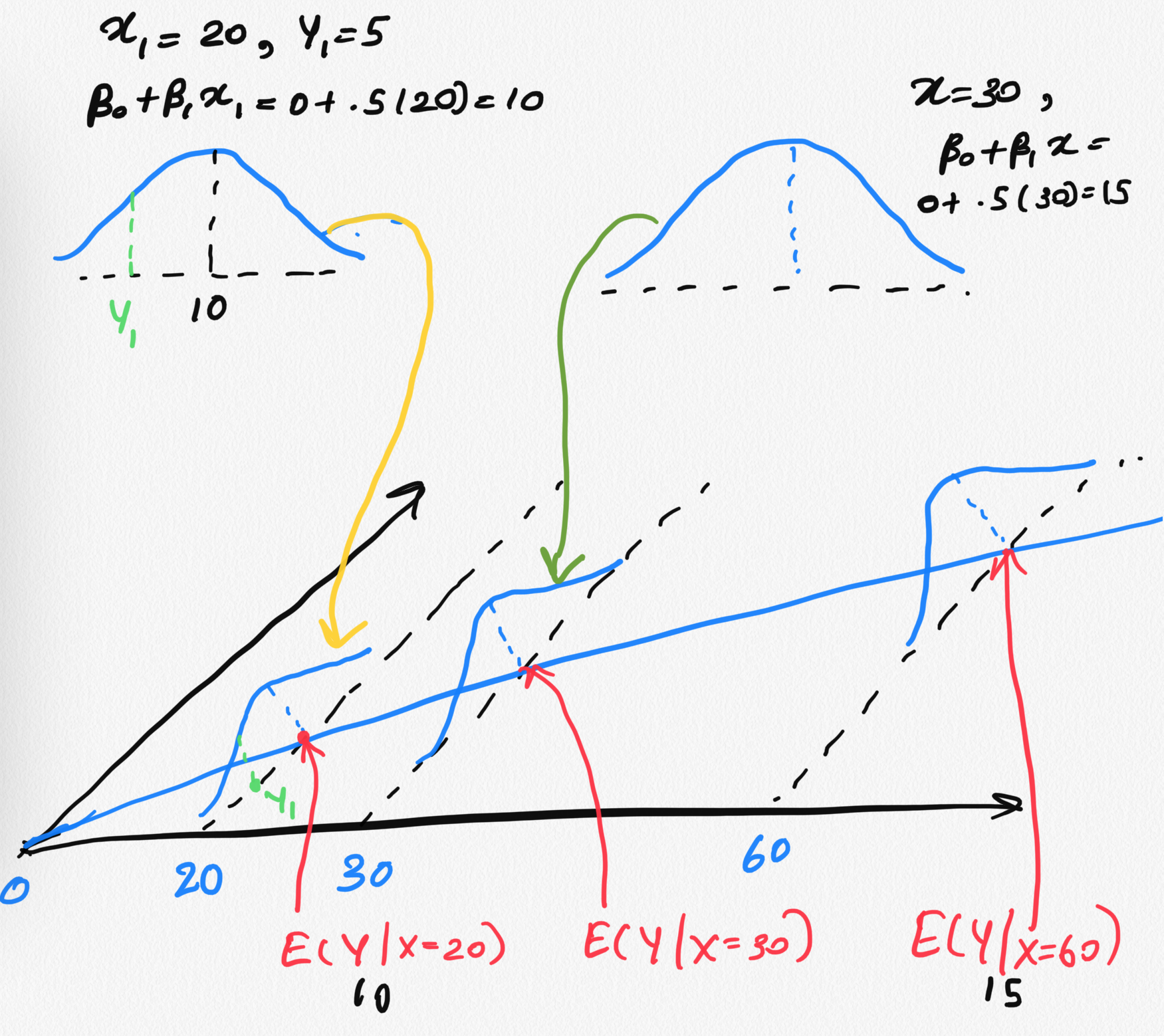 --- ## Model assumptions 1) The relationship between the response `\(Y\)` and the regressors is linear, at least approximately. --- ## Model assumptions 2) The error term `\(\epsilon\)` has zero mean. 3) The error term `\(\epsilon\)` has constant variance `\(\sigma^2\)`. 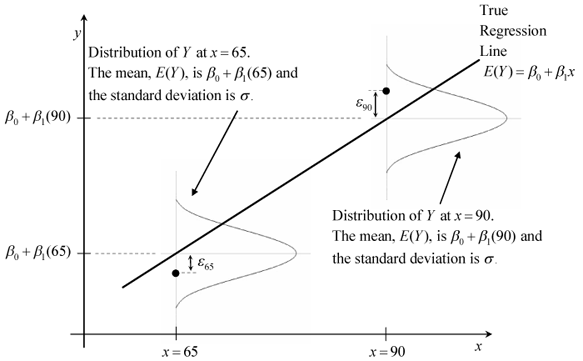 source: http://reliawiki.org/index.php/Simple_Linear_Regression_Analysis --- ## Model assumptions 4) The error are uncorrelated. 5) The errors are normally distributed. > Taking together 4 and 5 imply the errors are independent random variables. > Assumption 5 is required for parametric statistical inference (Hypothesis testing, Interval estimation). --- ## Diagnosing violations of the assumptions Diagnosing methods are primarily based on model residuals. ## Residuals `$$e_i = \text{Observed value} - \text{Fitted value}$$` `$$e_i = y_i - \hat{Y_i}$$` - Deviation between the observed value (true value) and fitted value. --- ```r df <- alr3::heights df$fitted <- 30.7 + (0.52*df$M) head(df,10) ``` ``` Mheight Dheight fitted 1 59.7 55.1 61.744 2 58.2 56.5 60.964 3 60.6 56.0 62.212 4 60.7 56.8 62.264 5 61.8 56.0 62.836 6 55.5 57.9 59.560 7 55.4 57.1 59.508 8 56.8 57.6 60.236 9 57.5 57.2 60.600 10 57.3 57.1 60.496 ``` First fitted value: 30.7 + (0.52 * 59.7) = 61.744 --- ```r df <- alr3::heights df$fitted <- 30.7 + (0.52*df$M) df$residuals <- df$Dheight - df$fitted head(df,10) ``` ``` Mheight Dheight fitted residuals 1 59.7 55.1 61.744 -6.644 2 58.2 56.5 60.964 -4.464 3 60.6 56.0 62.212 -6.212 4 60.7 56.8 62.264 -5.464 5 61.8 56.0 62.836 -6.836 6 55.5 57.9 59.560 -1.660 7 55.4 57.1 59.508 -2.408 8 56.8 57.6 60.236 -2.636 9 57.5 57.2 60.600 -3.400 10 57.3 57.1 60.496 -3.396 ``` First fitted value: 30.7 + (0.52 * 59.7) = 61.744 First residual value: 55.1 - 61.744 = -6.644 - It is convenient to think of residuals as the realized or observed values of the model error. - Residuals have zero mean. - Residuals are **not** independent. --- ### Observation-level statistics: `augment()` ```r library(broom) library(tidyverse) model1_fitresid <- augment(model1) model1_fitresid ``` ``` # A tibble: 1,375 x 8 Dheight Mheight .fitted .resid .std.resid .hat .sigma .cooksd <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 55.1 59.7 62.3 -7.16 -3.16 0.00172 2.26 0.00862 2 56.5 58.2 61.4 -4.95 -2.19 0.00310 2.26 0.00743 3 56 60.6 62.7 -6.75 -2.98 0.00118 2.26 0.00523 4 56.8 60.7 62.8 -6.00 -2.65 0.00113 2.26 0.00397 5 56 61.8 63.4 -7.40 -3.27 0.000783 2.26 0.00418 6 57.9 55.5 60.0 -2.08 -0.923 0.00707 2.27 0.00303 7 57.1 55.4 59.9 -2.83 -1.25 0.00725 2.27 0.00574 8 57.6 56.8 60.7 -3.09 -1.37 0.00492 2.27 0.00461 9 57.2 57.5 61.1 -3.87 -1.71 0.00395 2.26 0.00579 10 57.1 57.3 61.0 -3.86 -1.71 0.00421 2.26 0.00616 # … with 1,365 more rows ``` --- class: duke-orange, center, middle # Residual analysis --- background-image: url('errors.PNG') background-position: right background-size: contain ## Plot of residuals vs fitted values .pull-left[ This is useful for detecting several common types of model inadequacies. ] --- ### Our example 1) The relationship between the response `\(Y\)` and the regressors is linear, at least approximately. (Residuals vs Fitted/ Residual vs X - this is optional in Simple Linear Regression) 2) The error term `\(\epsilon\)` has zero mean. (Residuals vs Fitted) 3) The error term `\(\epsilon\)` has constant variance `\(\sigma^2\)`. (Residuals vs Fitted) .pull-left[ Residuals vs Fitted 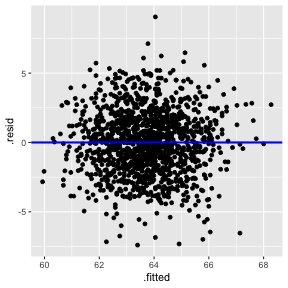<!-- --> ] .pull-right[ Residuals vs X <!-- --> ] --- ### Note In simple linear regression, it is not necessary to plot residuals versus both fitted values and regressor variable. The reason is fitted values are linear combinations of the regressor variable, so the plot would only differ in the scale for the abscissa. --- ## 4) The error are uncorrelated. - Often, we can conclude that the this assumption is sufficiently met based on a description of the data and how it was collected. > Use a random sample to ensure independence of observations. - If the time sequence in which the data were collected is known, plot of residuals in time sequence. --- ## 5) The errors are normally distributed. .pull-left[ ```r ggplot(model1_fitresid, aes(x=.resid))+ geom_histogram(colour="white")+ggtitle("Distribution of Residuals") ``` <!-- --> ] .pull-right[ ```r ggplot(model1_fitresid, aes(sample=.resid))+ stat_qq() + stat_qq_line()+labs(x="Theoretical Quantiles", y="Sample Quantiles") ``` <!-- --> ] ```r shapiro.test(model1_fitresid$.resid) ``` ``` Shapiro-Wilk normality test data: model1_fitresid$.resid W = 0.99859, p-value = 0.3334 ``` --- ## 5) The errors are normally distributed (cont.) `\(H0:\)` Errors are normally distributed. `\(H1:\)` Errors are not normally distributed. --- class: duke-orange, center, middle # Coefficient of Determination --- .pull-right[  ] .pull-left[ > Residuals measure the variability in the **response variable** not explained by the regression model. ] --- background-image: url('weight2.png') background-position: center background-size: contain --- ## Coefficient of Determination `$$R^2 = \frac{SS_M}{SS_T} = 1-\frac{SS_{R}}{SS_T}$$` `\(SS_T\)` - A measure of the variability in `\(y\)` without considering the effect of the regressor variable `\(x\)`. Measures the variation of `\(y\)` values around their mean. `\(SS_M\)` - Explained variation attributable to factors other than the relationship between `\(x\)` and `\(y\)`. Notation: `\(SS_{R}\)` or `\(SS_{E}\)` - A measure of the variability in `\(y\)` remaining after `\(x\)` has been considered. `\(R^2\)` - Proportion of variation in `\(Y\)` explained by the relation relationship of `\(Y\)` with `\(x\)`. --- ## Coefficient of Determination `$$0 \leq R^2 \leq 1$$`. Values of `\(R^2\)` that are close to 1 imply that most of the variability in `\(Y\)` is explained by the regression model. `\(R^2\)` should be interpreted with caution. (We will talk more on this in multiple linear regression analysis) --- ### Our example ```r summary(model1) ``` ``` Call: lm(formula = Dheight ~ Mheight, data = heights) Residuals: Min 1Q Median 3Q Max -7.397 -1.529 0.036 1.492 9.053 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 29.91744 1.62247 18.44 <2e-16 *** Mheight 0.54175 0.02596 20.87 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 2.266 on 1373 degrees of freedom Multiple R-squared: 0.2408, Adjusted R-squared: 0.2402 F-statistic: 435.5 on 1 and 1373 DF, p-value: < 2.2e-16 ``` `\(24\%\)` of the variability in daughter's height is accounted by the regression model. --- # `\(R^2\)` = 24.08% - Maybe you have one or more omitted variables. It is important to consider other factors that might influence the daughter's height: - Father's height - Physical activities performed by the daughter - Food nutrition, etc. - Maybe the functional form of the regression form is incorrect (so you have to add some quadratic, or cubic terms...). At the same time a transformation can be an alternative (if appropriate). - Maybe could be the effect of a group of outlier (maybe not one...). --- - A large `\(R^2\)` does not necessarily imply that the regression model will be an accurate predictor. - `\(R^2\)` does not measure the appropriateness of the linear model. - `\(R^2\)` will often large even though `\(Y\)` and `\(X\)` are nonlinearly related. --- ## Relationship between `\(r\)` and `\(R^2\)` ```r cor(heights$Mheight, heights$Dheight) ``` ``` [1] 0.4907094 ``` ```r cor(heights$Mheight, heights$Dheight)^2 ``` ``` [1] 0.2407957 ``` --- ## Is correlation enough? - Correlation is only a measure of association and is of little use in prediction. - Regression analysis is useful in developing a functional relationship between variables, which can be used for prediction and making inferences. --- ## Next Lecture > More work - Simple Linear Regression, Hypothesis testing, Predictions --- class: center, middle Acknowledgement Introduction to Linear Regression Analysis, Douglas C. Montgomery, Elizabeth A. Peck, G. Geoffrey Vining All rights reserved by [Dr. Thiyanga S. Talagala](https://thiyanga.netlify.app/)