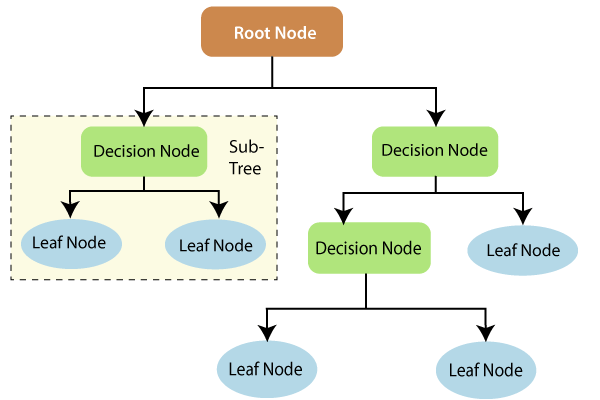
Classification and Regression Trees (CART)
Model
\[Y = f(X_1, X_2,... X_n) + \epsilon\] Goal: What is \(f\)?
How do we estimate \(f\) ?
Data-driven methods:
estimate \(f\) using observed data without making explicit assumptions about the functional form of \(f\).
Parametric methods:
estimate \(f\) using observed data by making assumptions about the functional form of \(f\).
Classification and Regression Trees
Classification tree - Outcome is categorical
Regression tree - Outcome is numeric
Classification and Regression Trees
CART models work by partitioning the feature space into a number of simple rectangular regions, divided up by axis parallel splits.
The splits are logical rules that split feature-space into two non-overlapping subregions.
Example: Feature space
Features: Sepal Length, Sepal Width
Outcome: setosa/versicolor
## Extracted only two species for easy explanation
data <- iris[1:100,]
library(ggplot2)
library(viridis)
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed()

Decision tree
# Load rpart and rpart.plot
library(rpart)
library(rpart.plot)
# Create a decision tree model
tree <- rpart(Species~Sepal.Length + Sepal.Width, data=data, cp=.02)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)

Decision tree
# Load rpart and rpart.plot
library(rpart)
library(rpart.plot)
# Create a decision tree model
tree <- rpart(Species~Sepal.Length + Sepal.Width, data=data, cp=.02)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)
Root node split
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed() + geom_vline(xintercept = 5.5)

Root node split, Decision node split - right
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed() + geom_vline(xintercept = 5.5) + geom_hline(yintercept = 3)

Root node split, Decision node splits
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed() + geom_vline(xintercept = 5.5) + geom_hline(yintercept = 3) + geom_hline(yintercept = 3.3)

Shallow decision tree
# Create a decision tree model
tree <- rpart(Species~Sepal.Length + Sepal.Width, data=data, cp=.5)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)

Two key ideas underlying trees
Recursive partitioning (for constructing the tree)
Pruning (for cutting the tree back)
Pruning is a useful strategy for avoiding over fitting.
There are some alternative methods to avoid over fitting as well.
Constructing Classification Trees
Recursive Partitioning
Main questions
Splitting variable
Which attribute/ feature should be placed at the root node?
Which features will act as internal nodes?
Splitting point
Looking for a split that increases the homogeneity (or “pure” as possible) of the resulting subsets.
Example
split that increases the homogeneity
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed()
Example (cont.)
split that increases the homogeneity .
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed() + geom_vline(xintercept = 5.5)
Key idea
Iteratively split variables into groups
Evaluate “homogeneity” within each group
Split again if necessary
How does a decision tree determine the best split?
Decision tree uses entropy and information gain to select a feature which gives the best split.
Gini index
Gini index for rectangle \(A\) is defined by
\[I(A) = 1- \sum_{k=1}^mp_k^2\]
\(p_k\) - proportion of records in rectangle \(A\) that belong to class \(k\)
- Gini index takes value 0 when all the records belong to the same class.
Gini index (cont)
In the two-class case Gini index is at peak when \(p_k = 0.5\)
Entropy measure
\[entropy(A) = - \sum_{k=1}^{m}p_k log_2(p_k)\]
Example: Calculation (left)
df <- data.frame(x=rep(c(2, 4, 6, 8), each=4),
y=rep(c(2, 4, 6, 8), times=4), col=factor(c(rep("red", 15), "blue")))
ggplot(df, aes(x=x, y=y, col=col)) + geom_point(size=4)

Example: calculation (right) (cont.)
df <- data.frame(x=rep(c(2, 4, 6, 8), each=4),
y=rep(c(2, 4, 6, 8), times=4), col=factor(c(rep("red", 8), rep("blue", 8))))
ggplot(df, aes(x=x, y=y, col=col)) + geom_point(size=4)

Finding the best threshold split?
In-class demonstration
Overfitting in decision trees
Overfitting refers to the condition when the model completely fits the training data but fails to generalize the testing unseen data.
If a decision tree is fully grown or when you increase the depth of the decision tree, it may lose some generalization capability.
Pruning is a technique that is used to reduce overfitting. Pruning simplifies a decision tree by removing the weakest rules.
Stopping criteria
Tree depth (number of splits)
Minimum number of records in a terminal node
Minimum reduction in impurity
Complexity parameter (\(CP\) ) - available in rpart package
Pre-pruning (early stopping)
max_depth
min_samples_leaf
min_samples_split
Post pruning
Simplify the tree after the learning algorithm terminates
The idea here is to allow the decision tree to grow fully and observe the CP value
Simplify the tree after the learning algorithm terminates
- Complexity of tree is measured by number of leaves.
\(L(T) = \text{number of leaf nodes}\)
The more leaf nodes you have, the more complexity.
We need a balance between complexity and predictive power
Total cost = measure of fit + measure of complexity
Total cost = measure of fit + measure of complexity
measure of fit: error
measure of complexity: number of leaf nodes (\(L(T)\))
\(\text{Total cost } (C(T)) = Error(T) + \lambda L(T)\)
The parameter \(\lambda\) trade off between complexity and predictive power. The parameter \(\lambda\) is a penalty factor for tree size.
\(\lambda = 0\): Fully grown decision tree
\(\lambda = \infty\): Root node only
\(\lambda\) between 0 and \(\infty\) balance predictive power and complexity.
Example: candidate for pruning (in-class)
# Load rpart and rpart.plot
library(rpart)
library(rpart.plot)
# Create a decision tree model
tree <- rpart(Species~Sepal.Length + Sepal.Width, data=data, cp=.02)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)
Classification trees - label of terminal node

labels are based on majority votes.
Regression Trees
# Load rpart and rpart.plot
library(rpart)
library(rpart.plot)
# Create a decision tree model
tree <- rpart(Petal.Length~Sepal.Length + Sepal.Width, data=data, cp=.02)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)

Regression Trees
Value of the terminal node: average outcome value of the training records that were in that terminal node.
Your turn: Impurity measures for regression tree
Decision trees - advantages
Decision trees - disadvantages
Decision Tree
data <- iris[1:100,]
library(rpart)
library(rpart.plot)
# Create a decision tree model
tree <- rpart(Species~Sepal.Length + Sepal.Width, data=data, cp=.02)
# Visualize the decision tree with rpart.plot
rpart.plot(tree, box.palette="RdBu", shadow.col="gray", nn=TRUE)
Decision boundary
library(tidyverse)
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, col=Species)) + geom_point() + scale_color_manual(values = c("#1b9e77", "#d95f02")) + coord_fixed() + geom_vline(xintercept = 5.5) + geom_hline(yintercept = 3) + geom_hline(yintercept = 3.3)
Decision trees - Limitation
To capture a complex decision boundary we need to use a deep tree
In-class explanation
Bias-Variance Tradeoff
- A deep decision tree has low bias and high variance.

Bagging (Bootstrap Aggregation)
Technique for reducing the variance of an estimated predicted function
Works well for high-variance, low-bias procedures, such as trees
Ensemble Methods
“Ensemble learning gives credence to the idea of the “wisdom of crowds,” which suggests that the decision-making of a larger group of people is typically better than that of an individual expert.”
Source: https://www.ibm.com/cloud/learn/boosting
Bootstrap
- Generate multiple samples of training data, via bootstrapping
Example
Training data: \(\{(y_1, x_1), (y_2, x_2), (y_3, x_3), (y_4, x_4)\}\)
Three samples generated from bootstrapping
Sample 1 = \(\{(y_1, x_1), (y_2, x_2), (y_3, x_3), (y_4, x_4)\}\)
Sample 2 = \(\{(y_1, x_1), (y_1, x_1), (y_1, x_1), (y_4, x_4)\}\)
Sample 3 = \(\{(y_1, x_1), (y_2, x_2), (y_1, x_1), (y_4, x_4)\}\)
Bagging - in class diagram
Bagging
Pros
Ease of implementation
Reduction of variance
Cons
Bagging
Bootstrapped subsamples are created
A Decision Tree is formed on each bootstrapped sample.
The results of each tree are aggregated
Random Forests: Improving on Bagging
The ensembles of trees in Bagging tend to be highly correlated.
All of the bagged trees will look quite similar to each other. Hence, the predictions from the bagged trees will be highly correlated.
Random Forests
Bootstrap samples
At each split, randomly select a set of predictors from the full set of predictors
From the selected predictors we select the optimal predictor and the optimal corresponding threshold for the split.
Grow multiple trees and aggregate
Random Forests - Hyper parameters
Number of variables randomly sampled as candidates at each split
Number of trees to grow
Minimum size of terminal nodes. Setting this number larger causes smaller trees to be grown (and thus take less time).
Note: In theory, each tree in the random forest is full (not pruned), but in practice this can be computationally expensive,thus, imposing a minimum node size is not unusual.
Random Forests
Pros
Cons
Speed
Interpretability
Overfitting
Out-of-bag error
With ensemble methods, we get a new metric for assessing the predictive performance of the model, the out-of-bag error
Random Forests

Random Forests

Out-of-Bag (OOB) Samples

Out-of-Bag (OOB) Samples

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Predictions based on OOB observations

Variable Importance in Random Forest
contribution to predictive accuracy
Permutation-based variable importance
the OOB samples are passed down the tree, and the prediction accuracy is recorded
the values for the \(j^{th}\) variable are randomly permuted in the OOB samples, and the accuracy is again computed.
the decrease in accuracy as a result of this permuting is averaged over all trees, and is used as a measure of the importance of variable \(j\) in the random forests
Mean decrease in Gini coefficient
Measure of how each variable contributes to the homogeneity of the nodes and leaves in the resulting random forest
The higher the value of mean decrease accuracy or mean decrease Gini score, the higher the importance of the variable in the model
Practical Session
Packages
library(tidymodels)
## ── Attaching packages ────────────────────────────────────── tidymodels 1.0.0 ──
## ✔ broom 1.0.0 ✔ rsample 1.1.0
## ✔ dials 1.0.0 ✔ tune 1.0.0
## ✔ infer 1.0.2 ✔ workflows 1.0.0
## ✔ modeldata 1.0.0 ✔ workflowsets 1.0.0
## ✔ parsnip 1.0.0 ✔ yardstick 1.0.0
## ✔ recipes 1.0.1
## ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
## ✖ scales::discard() masks purrr::discard()
## ✖ dplyr::filter() masks stats::filter()
## ✖ recipes::fixed() masks stringr::fixed()
## ✖ dplyr::lag() masks stats::lag()
## ✖ dials::prune() masks rpart::prune()
## ✖ yardstick::spec() masks readr::spec()
## ✖ recipes::step() masks stats::step()
## • Use suppressPackageStartupMessages() to eliminate package startup messages
library(tidyverse)
library(palmerpenguins)
##
## Attaching package: 'palmerpenguins'
## The following object is masked from 'package:modeldata':
##
## penguins
library(rpart)
library(skimr)
library(rpart.plot)
Data
data(penguins)
skim(penguins)
Data summary
| Name |
penguins |
| Number of rows |
344 |
| Number of columns |
8 |
| _______________________ |
|
| Column type frequency: |
|
| factor |
3 |
| numeric |
5 |
| ________________________ |
|
| Group variables |
None |
Variable type: factor
| species |
0 |
1.00 |
FALSE |
3 |
Ade: 152, Gen: 124, Chi: 68 |
| island |
0 |
1.00 |
FALSE |
3 |
Bis: 168, Dre: 124, Tor: 52 |
| sex |
11 |
0.97 |
FALSE |
2 |
mal: 168, fem: 165 |
Variable type: numeric
| bill_length_mm |
2 |
0.99 |
43.92 |
5.46 |
32.1 |
39.23 |
44.45 |
48.5 |
59.6 |
▃▇▇▆▁ |
| bill_depth_mm |
2 |
0.99 |
17.15 |
1.97 |
13.1 |
15.60 |
17.30 |
18.7 |
21.5 |
▅▅▇▇▂ |
| flipper_length_mm |
2 |
0.99 |
200.92 |
14.06 |
172.0 |
190.00 |
197.00 |
213.0 |
231.0 |
▂▇▃▅▂ |
| body_mass_g |
2 |
0.99 |
4201.75 |
801.95 |
2700.0 |
3550.00 |
4050.00 |
4750.0 |
6300.0 |
▃▇▆▃▂ |
| year |
0 |
1.00 |
2008.03 |
0.82 |
2007.0 |
2007.00 |
2008.00 |
2009.0 |
2009.0 |
▇▁▇▁▇ |
Split data
set.seed(123)
penguin_split <- initial_split(penguins)
penguin_train <- training(penguin_split)
dim(penguin_train)
## [1] 258 8
head(penguin_train)
## # A tibble: 6 × 8
## species island bill_length_mm bill_depth_mm flipper…¹ body_…² sex year
## <fct> <fct> <dbl> <dbl> <int> <int> <fct> <int>
## 1 Gentoo Biscoe 44.5 14.3 216 4100 <NA> 2007
## 2 Adelie Torgersen 38.6 21.2 191 3800 male 2007
## 3 Gentoo Biscoe 45.3 13.7 210 4300 fema… 2008
## 4 Chinstrap Dream 52.8 20 205 4550 male 2008
## 5 Adelie Torgersen 37.3 20.5 199 3775 male 2009
## 6 Chinstrap Dream 43.2 16.6 187 2900 fema… 2007
## # … with abbreviated variable names ¹flipper_length_mm, ²body_mass_g
penguin_test <- testing(penguin_split)
dim(penguin_test)
## [1] 86 8
Build decision tree
tree1 <- rpart(species ~ ., penguin_train, cp = 0.1)
rpart.plot(tree1, box.palette="RdBu", shadow.col="gray", nn=TRUE)

tree2 <- rpart(species ~ ., penguin_train, cp = 0.5)
rpart.plot(tree2, box.palette="RdBu", shadow.col="gray", nn=TRUE)

Predict
predict(tree1, penguin_test)
## Adelie Chinstrap Gentoo
## 1 0.95726496 0.04273504 0.00000000
## 2 0.95726496 0.04273504 0.00000000
## 3 0.95726496 0.04273504 0.00000000
## 4 0.95726496 0.04273504 0.00000000
## 5 0.95726496 0.04273504 0.00000000
## 6 0.95726496 0.04273504 0.00000000
## 7 0.95726496 0.04273504 0.00000000
## 8 0.95726496 0.04273504 0.00000000
## 9 0.95726496 0.04273504 0.00000000
## 10 0.95726496 0.04273504 0.00000000
## 11 0.95726496 0.04273504 0.00000000
## 12 0.95726496 0.04273504 0.00000000
## 13 0.95726496 0.04273504 0.00000000
## 14 0.95726496 0.04273504 0.00000000
## 15 0.95726496 0.04273504 0.00000000
## 16 0.95726496 0.04273504 0.00000000
## 17 0.95726496 0.04273504 0.00000000
## 18 0.95726496 0.04273504 0.00000000
## 19 0.95726496 0.04273504 0.00000000
## 20 0.95726496 0.04273504 0.00000000
## 21 0.95726496 0.04273504 0.00000000
## 22 0.04545455 0.93181818 0.02272727
## 23 0.95726496 0.04273504 0.00000000
## 24 0.95726496 0.04273504 0.00000000
## 25 0.95726496 0.04273504 0.00000000
## 26 0.95726496 0.04273504 0.00000000
## 27 0.95726496 0.04273504 0.00000000
## 28 0.95726496 0.04273504 0.00000000
## 29 0.01030928 0.04123711 0.94845361
## 30 0.95726496 0.04273504 0.00000000
## 31 0.95726496 0.04273504 0.00000000
## 32 0.95726496 0.04273504 0.00000000
## 33 0.95726496 0.04273504 0.00000000
## 34 0.95726496 0.04273504 0.00000000
## 35 0.95726496 0.04273504 0.00000000
## 36 0.95726496 0.04273504 0.00000000
## 37 0.95726496 0.04273504 0.00000000
## 38 0.01030928 0.04123711 0.94845361
## 39 0.01030928 0.04123711 0.94845361
## 40 0.01030928 0.04123711 0.94845361
## 41 0.01030928 0.04123711 0.94845361
## 42 0.01030928 0.04123711 0.94845361
## 43 0.01030928 0.04123711 0.94845361
## 44 0.01030928 0.04123711 0.94845361
## 45 0.01030928 0.04123711 0.94845361
## 46 0.01030928 0.04123711 0.94845361
## 47 0.01030928 0.04123711 0.94845361
## 48 0.01030928 0.04123711 0.94845361
## 49 0.01030928 0.04123711 0.94845361
## 50 0.01030928 0.04123711 0.94845361
## 51 0.01030928 0.04123711 0.94845361
## 52 0.01030928 0.04123711 0.94845361
## 53 0.01030928 0.04123711 0.94845361
## 54 0.01030928 0.04123711 0.94845361
## 55 0.01030928 0.04123711 0.94845361
## 56 0.01030928 0.04123711 0.94845361
## 57 0.01030928 0.04123711 0.94845361
## 58 0.01030928 0.04123711 0.94845361
## 59 0.01030928 0.04123711 0.94845361
## 60 0.01030928 0.04123711 0.94845361
## 61 0.01030928 0.04123711 0.94845361
## 62 0.01030928 0.04123711 0.94845361
## 63 0.01030928 0.04123711 0.94845361
## 64 0.01030928 0.04123711 0.94845361
## 65 0.01030928 0.04123711 0.94845361
## 66 0.01030928 0.04123711 0.94845361
## 67 0.01030928 0.04123711 0.94845361
## 68 0.01030928 0.04123711 0.94845361
## 69 0.04545455 0.93181818 0.02272727
## 70 0.04545455 0.93181818 0.02272727
## 71 0.04545455 0.93181818 0.02272727
## 72 0.04545455 0.93181818 0.02272727
## 73 0.04545455 0.93181818 0.02272727
## 74 0.04545455 0.93181818 0.02272727
## 75 0.04545455 0.93181818 0.02272727
## 76 0.04545455 0.93181818 0.02272727
## 77 0.04545455 0.93181818 0.02272727
## 78 0.04545455 0.93181818 0.02272727
## 79 0.04545455 0.93181818 0.02272727
## 80 0.04545455 0.93181818 0.02272727
## 81 0.04545455 0.93181818 0.02272727
## 82 0.04545455 0.93181818 0.02272727
## 83 0.04545455 0.93181818 0.02272727
## 84 0.01030928 0.04123711 0.94845361
## 85 0.95726496 0.04273504 0.00000000
## 86 0.04545455 0.93181818 0.02272727
t_pred <- predict(tree1, penguin_test, type = "class")
t_pred
## 1 2 3 4 5 6 7 8
## Adelie Adelie Adelie Adelie Adelie Adelie Adelie Adelie
## 9 10 11 12 13 14 15 16
## Adelie Adelie Adelie Adelie Adelie Adelie Adelie Adelie
## 17 18 19 20 21 22 23 24
## Adelie Adelie Adelie Adelie Adelie Chinstrap Adelie Adelie
## 25 26 27 28 29 30 31 32
## Adelie Adelie Adelie Adelie Gentoo Adelie Adelie Adelie
## 33 34 35 36 37 38 39 40
## Adelie Adelie Adelie Adelie Adelie Gentoo Gentoo Gentoo
## 41 42 43 44 45 46 47 48
## Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
## 49 50 51 52 53 54 55 56
## Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
## 57 58 59 60 61 62 63 64
## Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo Gentoo
## 65 66 67 68 69 70 71 72
## Gentoo Gentoo Gentoo Gentoo Chinstrap Chinstrap Chinstrap Chinstrap
## 73 74 75 76 77 78 79 80
## Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap Chinstrap
## 81 82 83 84 85 86
## Chinstrap Chinstrap Chinstrap Gentoo Adelie Chinstrap
## Levels: Adelie Chinstrap Gentoo
Accuracy
confMat <- table(penguin_test$species,t_pred)
confMat
## t_pred
## Adelie Chinstrap Gentoo
## Adelie 35 1 1
## Chinstrap 1 16 1
## Gentoo 0 0 31
Random forest
# packages
library(tidyverse)
library(randomForest)
## randomForest 4.7-1.1
## Type rfNews() to see new features/changes/bug fixes.
##
## Attaching package: 'randomForest'
## The following object is masked from 'package:dplyr':
##
## combine
## The following object is masked from 'package:ggplot2':
##
## margin
# Split data
data(iris)
df <- iris %>% mutate(id = row_number())
## set the seed to make your partition reproducible
set.seed(123)
train <- df %>% sample_frac(.80)
dim(train)
## [1] 120 6
test <- anti_join(df, train, by = 'id')
dim(test)
## [1] 30 6
# Model building
?randomForest
rf1 <- randomForest(Species ~ Sepal.Length+
Sepal.Width+ Petal.Length +
Petal.Width,
data=train)
rf1
##
## Call:
## randomForest(formula = Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width, data = train)
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 4.17%
## Confusion matrix:
## setosa versicolor virginica class.error
## setosa 40 0 0 0.00000000
## versicolor 0 32 3 0.08571429
## virginica 0 2 43 0.04444444
rf2 <- randomForest(Species ~ Sepal.Length+
Sepal.Width+ Petal.Length +
Petal.Width,
data=train, ntree=1000)
rf2
##
## Call:
## randomForest(formula = Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width, data = train, ntree = 1000)
## Type of random forest: classification
## Number of trees: 1000
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 4.17%
## Confusion matrix:
## setosa versicolor virginica class.error
## setosa 40 0 0 0.00000000
## versicolor 0 32 3 0.08571429
## virginica 0 2 43 0.04444444
rf3 <- randomForest(Species ~ Sepal.Length+
Sepal.Width+ Petal.Length +
Petal.Width,
data=train, ntree=1000,
mtry=3)
rf3
##
## Call:
## randomForest(formula = Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width, data = train, ntree = 1000, mtry = 3)
## Type of random forest: classification
## Number of trees: 1000
## No. of variables tried at each split: 3
##
## OOB estimate of error rate: 4.17%
## Confusion matrix:
## setosa versicolor virginica class.error
## setosa 40 0 0 0.00000000
## versicolor 0 32 3 0.08571429
## virginica 0 2 43 0.04444444
Obtain predictions for the test set
pred <- predict(rf2, test)
pred
## 1 2 3 4 5 6 7
## setosa setosa setosa setosa setosa setosa setosa
## 8 9 10 11 12 13 14
## setosa setosa setosa versicolor versicolor versicolor versicolor
## 15 16 17 18 19 20 21
## versicolor versicolor versicolor versicolor versicolor versicolor versicolor
## 22 23 24 25 26 27 28
## versicolor virginica versicolor versicolor virginica virginica virginica
## 29 30
## virginica virginica
## Levels: setosa versicolor virginica
table(pred, test$Species)
##
## pred setosa versicolor virginica
## setosa 10 0 0
## versicolor 0 14 0
## virginica 0 1 5
## variable importance
varImpPlot(rf2, sort=T, main="Variable Importance")

## variable importance table
var.imp <- data.frame(importance(rf2, type=2))
var.imp
## MeanDecreaseGini
## Sepal.Length 7.937010
## Sepal.Width 1.967727
## Petal.Length 35.391987
## Petal.Width 33.556159

{kind=link}